LLMs make it easy to build features, but hard to build margins. Here’s why — and how to fix it.
The Broken Promise of AI Margins
Traditional software has an economic model that’s the envy of every other industry: you pay a fixed cost to build the product, but near-zero marginal costs to serve it. Whether you have ten users or ten thousand, the cost of the next request is negligible. This “build once, sell forever” dynamic is the foundation of SaaS.
When the current AI boom began, many companies looked at LLMs as a “cheat code” to bypass the hard part of this equation. The naive hope was to skip the heavy fixed costs of traditional engineering – the development work, complex logic, and specialized talent – and skip straight to the high-margin profits of software.
To their credit, they were half right. LLMs do lower the upfront development cost, sometimes dramatically. You can prototype complex features in an afternoon that used to take months. But the rub comes after you launch: you discover that, rather than removing cost, you’ve delayed it. And in doing so, you’ve converted a fixed cost to a fixed marginal cost. Instead of a one-time fixed cost, you are now paying a constant, unyielding marginal “tax” on every single interaction.
Teams expecting software margins are ending up with utility margins (at best).
Why do so many AI products fail the fundamental test of software economics?
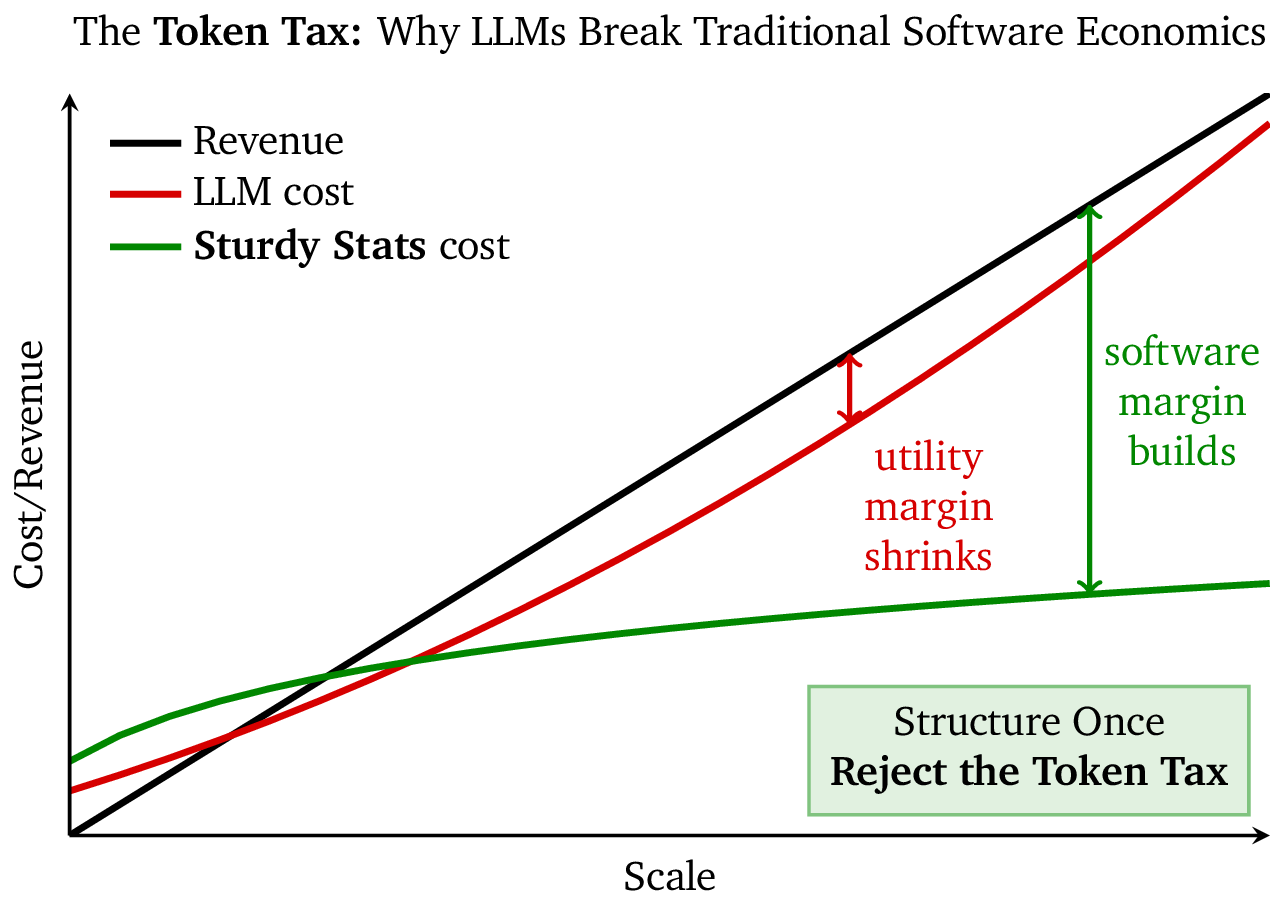
The Token Tax: Why Scale Hurts
Large Language Models (LLMs) behave less like software assets you own and more like metered utilities you rent.
In traditional software, logic is explicit in the code and state is preserved. In LLM architectures, on the other hand, logic is implicit in the model context and can only be retrieved via “prompting.” Thus, you pay a recurring toll – a “Token Tax” – on every single interaction.
Moreover, because models are stateless, they have amnesia; long-term memory must be re-supplied on each call. To answer a follow-up question, you must pay to re-feed the model the original context, plus the new question, plus the history of the conversation.
This is a simple fact about LLM architecture, but its economic implications are punishing:
- Linear (or worse) Cost Scaling: There is no natural point where marginal costs taper off.
- Context Inflation: As features mature, prompts get longer. You pay more for the same user action in month 12 than you did in month 1 because you are stuffing more context, more examples, and more safeguards into the window.
- Zero Amortization: You are billed every time the model re-interprets the same text. You never “own” the processing work.
Agentic Workflows Multiply the Problem
The industry is currently pivoting toward “Agentic Workflows:” multi-step processes where models plan, search, tool-use, and refine. While this may improve a product’s performance, it wreaks havoc on its unit economics. A single user request now triggers a chain reaction of planning loops, self-correction, and tool routing. What looks like one API call to the user may be a dozen or more calls on the backend.
Consequently, COGS (Cost of Goods Sold) increases directly with product sophistication.
“I’ve spoken with 20+ AI founders… They all said the same thing: ‘We’re scaling… but token costs and latency are starting to hit us hard.’… As you scale, agents start re-querying the same info, looping through tools, and sending massive context windows. The result? Cost and latency grow faster than usage.” — [Gleb Gordeev via LinkedIn]
This removes the primary advantage of software. If your costs grow in lockstep with your revenue, you aren’t building a SaaS company; you are building a services firm with robotic employees.
The Solution: Structure Once, Query Cheaply
The mistake lies in treating LLMs as end-to-end data processors. Modern AI workloads are expensive because they repeatedly re-read raw, unstructured text. Sending entire documents to an LLM just to extract a single answer is economically inefficient.
The obvious solution is to shift from a Variable Cost model (re-reading text every time) to a Fixed Cost model (structuring text once).
The Trap of Unstructured Data
We often reach for LLMs simply because our data is messy and traditional software struggles with that unstructured data. But this choice is often a one-way street: because knowledge and structure are implicit in LLMs, once your workflow enters an LLM, it tends to stay there. As we discuss in our companion post The Trap of Unstructured Data: Why We Over-Delegate to LLMs, you end up trapping your data inside a probabilistic model, forcing you to pay for reasoning when you really just wanted reading. You may have chosen the model simply to handle your data format, but you end up paying it to perform your logic, your analysis, and your value judgments too.
This is where Sturdy Statistics changes the picture.
Sturdy Statistics ingests your unstructured data and converts it into structured, queryable records. You pay the compute cost to “read” the document exactly once. (With our flat monthly fee, your marginal cost is predictable, decoupled from your usage, and scales away as you grow.)
Once the data is structured, you regain control of your architecture:
- Zero-Inference Queries: Many user questions can be answered via business logic or standard SQL, bypassing the LLM entirely. This is deterministic, lightning-fast, and free.
- Targeted Context: When reasoning is required, you send the LLM only the precise, relevant rows—not the whole document. This unlocks the “oracle” mode of LLM use: cheaper, faster, more accurate, and more repeatable than long-context or agentic workflows.
Conclusion: Restoring Software Economics
With Sturdy Statistics, token usage grows sub-linearly relative to your user base. New data makes the system smarter, but not more expensive to query.
To build a viable business on top of AI, you must reject the Token Tax. Stop paying a model to read the same document a thousand times. Pay to structure it once, and let your margins scale like software again.
If you’re building on LLMs and starting to feel the Token Tax, it’s not simply a pricing problem; it’s architectural. We’d be happy to walk through your current workflow and show you where structure can restore your margins.